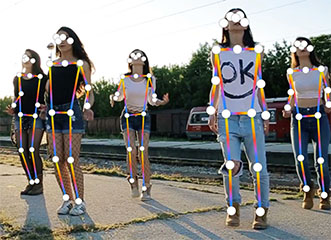View in English
无需机器学习的相关经验,也能利用专为直接与 app 整合而设计的机器学习功能。
构建相关功能,以使用计算机视觉来处理和分析图像与视频。
查看 计算机视觉 框架 (英文)
自动识别图像内容。
查看 API (英文)
量化并直观地呈现图像的关键部分,或者图像中人们可能会注意到的地方。
分析和管理图像的对齐。
生成特征打印来计算图像之间的距离。
查找和标记图像中的物体。
追踪视频中的移动对象。
检测视频中运动物体的轨迹。
追踪图像和视频中物体边缘及特征。
检测图像中可见文本的区域。
从图像中查找、识别和提取文本。
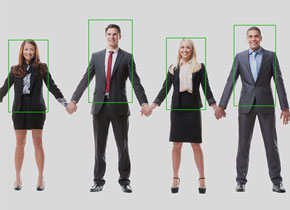
检测图像中的人脸。
在相机视频流中实时追踪人脸。
通过检测面部特征点,在图像中找到面部特征。
比较一组图像中的面部捕捉质量。
查找图像中包含人体的区域。
检测图像和视频中人物的特征点。
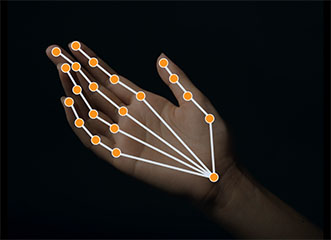
检测图像和视频中人物手部的特征点。
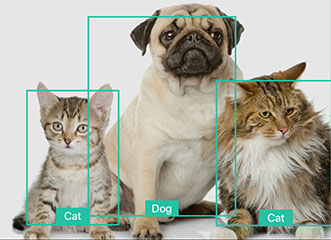
查找图像中的猫和狗。
检测和分析图像中的条形码。
查找图像中的矩形区域。
确定图像中的地平线角度。
分析连续视频帧之间物体的运动模式。
为图像中的人物生成一个蒙版图像。
检测图像中含有文本的矩形区域。
分析自然语言文本并推断其基于不同语言的元数据。
查看 自然语言 框架 (英文)
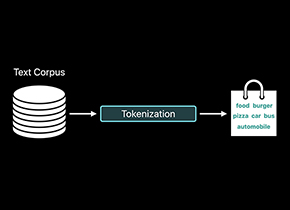
枚举文本字符串中的单词。
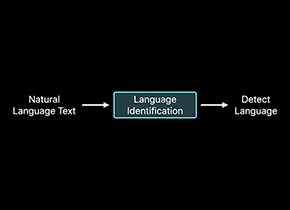
识别正文部分的语言。
使用语言标记来命名字符串中的实体。
对字符串中的名词、动词、形容词等词性进行分类。
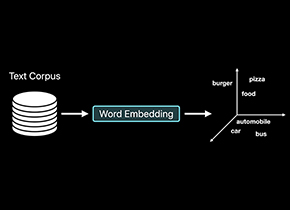
为任意单词创建矢量表示,并找出两个单词之间的相似性或最相近的单词。
为任意字符串创建矢量表示,并找出两个字符串之间的相似性。
根据文本的情感,将文本分为积极、消极或中立。
利用适用于多种语言的语音识别和显著性功能。
查看 语音 框架 (英文)
识别和分析音频中的语音,并获取对话记录等数据。
分析音频并将它识别为特定类型,例如笑声或掌声。
查看 声音分析 框架 (英文)
利用内置的声音分类器或自定 Core ML 声音分类模型来分析音频中的声音。