struct MLImageClassifier (英語)
画像を分類するためにトレーニングするモデル。
struct MLObjectDetector (英語)
画像内の1つ以上のオブジェクトを分類するためにトレーニングするモデル。
画像分類器は、画像を認識する機械学習モデルです。画像分類器に画像を渡すと、画像分類器はその画像のカテゴリラベルを返します。

画像分類器をトレーニングするには、すでにラベル付けされた画像サンプルを多数見せます。たとえば、ゾウ、キリン、ライオンなどのさまざまな写真を見せることによって、野生動物を識別する画像分類器をトレーニングできます。
画像分類器のトレーニングが終了したら、モデルの精度を評価し、モデルのパフォーマンスが十分である場合は、結果をCore MLモデルファイルとして保存します。次に、このモデルファイルをXcodeプロジェクトにインポートすると、アプリで画像分類器を使うことができます。
カテゴリごとに少なくとも10枚以上の画像を使いますが、画像分類器のパフォーマンスは、使用される画像が多様なほど(さまざまなアングルや撮影時の照明条件など)向上することに留意してください。
カテゴリごとの画像数のバランスにも配慮してください。たとえば、あるカテゴリで10枚の画像を使い、別のカテゴリでは1000枚使うようなことは避けてください。
画像の形式は、JPEGやPNGなど、Quicktime Playerで開くことができれば何でもかまいません。画像は特定のサイズにする必要はなく、それぞれを同じサイズにする必要もありません。ただし、299x299ピクセル以上の大きさの画像を使うことをおすすめします。
可能であれば、そのモデルをアプリで使うときに想定される画像にできるだけ近い画像を収集してください。たとえば、デバイスのカメラで屋外の設定で撮影された画像を分類するアプリの場合は、同じようなタイプのカメラで屋外撮影された画像を使ってモデルをトレーニングします。
画像をサブフォルダに分類することでトレーニングデータセットを準備します。各サブフォルダに、格納される画像のカテゴリを示す名前を付けます。たとえば、すべてのチーターの画像にはCheetahというラベルを使います。

テスト用のデータセットを使ってモデルをテストすると、トレーニング済みモデルの実稼働環境でのパフォーマンスを簡単に確認できます。
十分な数の画像(たとえば、カテゴリごとに25枚以上)がある場合、トレーニングデータセットのフォルダ構造を複製してテスト用のデータセットを作成します。次に、各カテゴリの画像の約20%をテスト用データセットの対応するカテゴリフォルダに移動します。
Create MLを使って、画像分類プロジェクトを作成します。Xcodeを開いた状態で、Controlキーを押しながらDock内の「Xcode」アイコンをクリックし、「Open Developer Tool」>「Create ML」の順に選択します(または、Xcodeのメニューから、「Open Developer Tool>「Create ML」の順に選択します)。
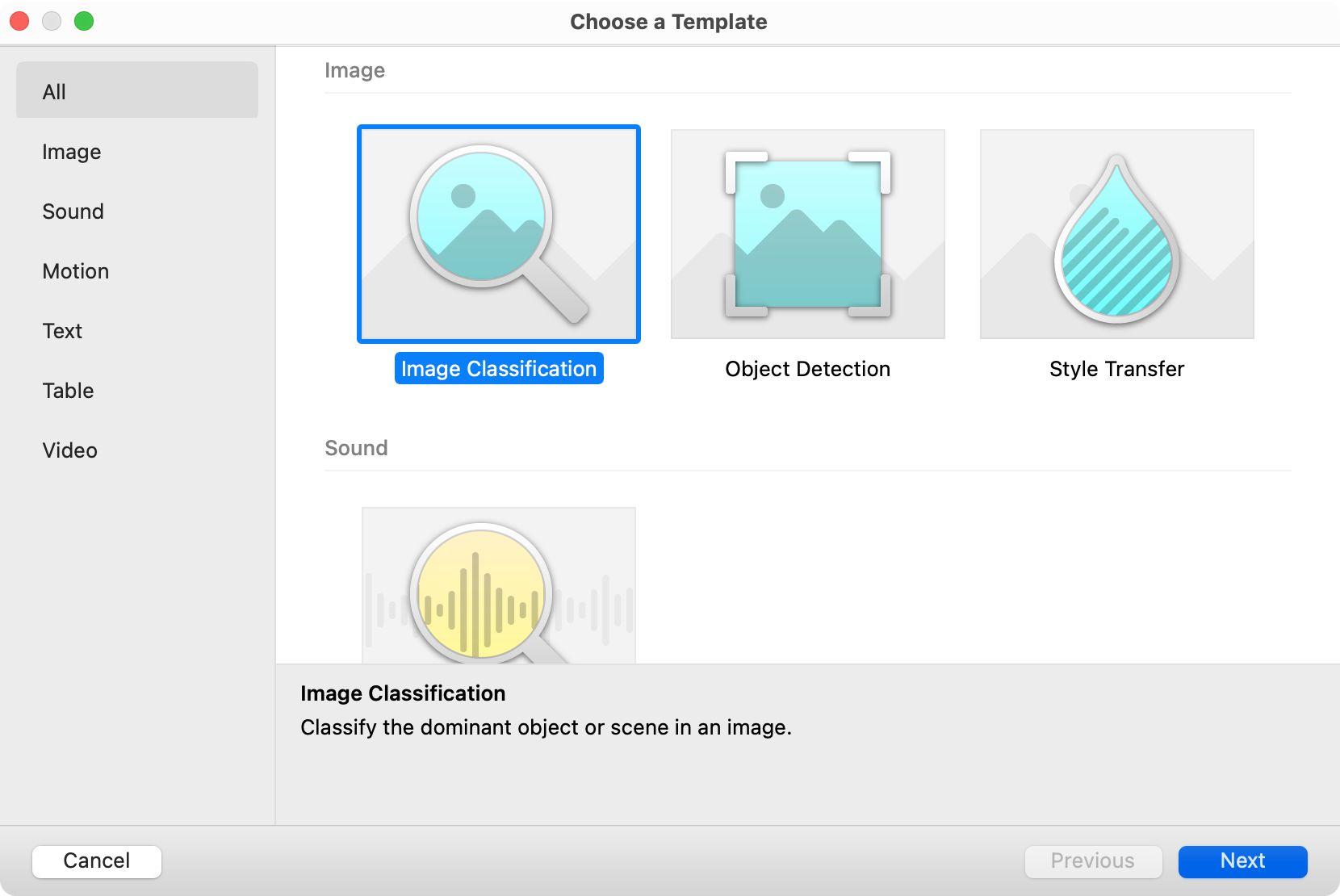
Create MLで、「File」>「New Project」の順に選択して、モデルテンプレートのリストを表示します。「Image Classification」を選択し、「Next」をクリックします。
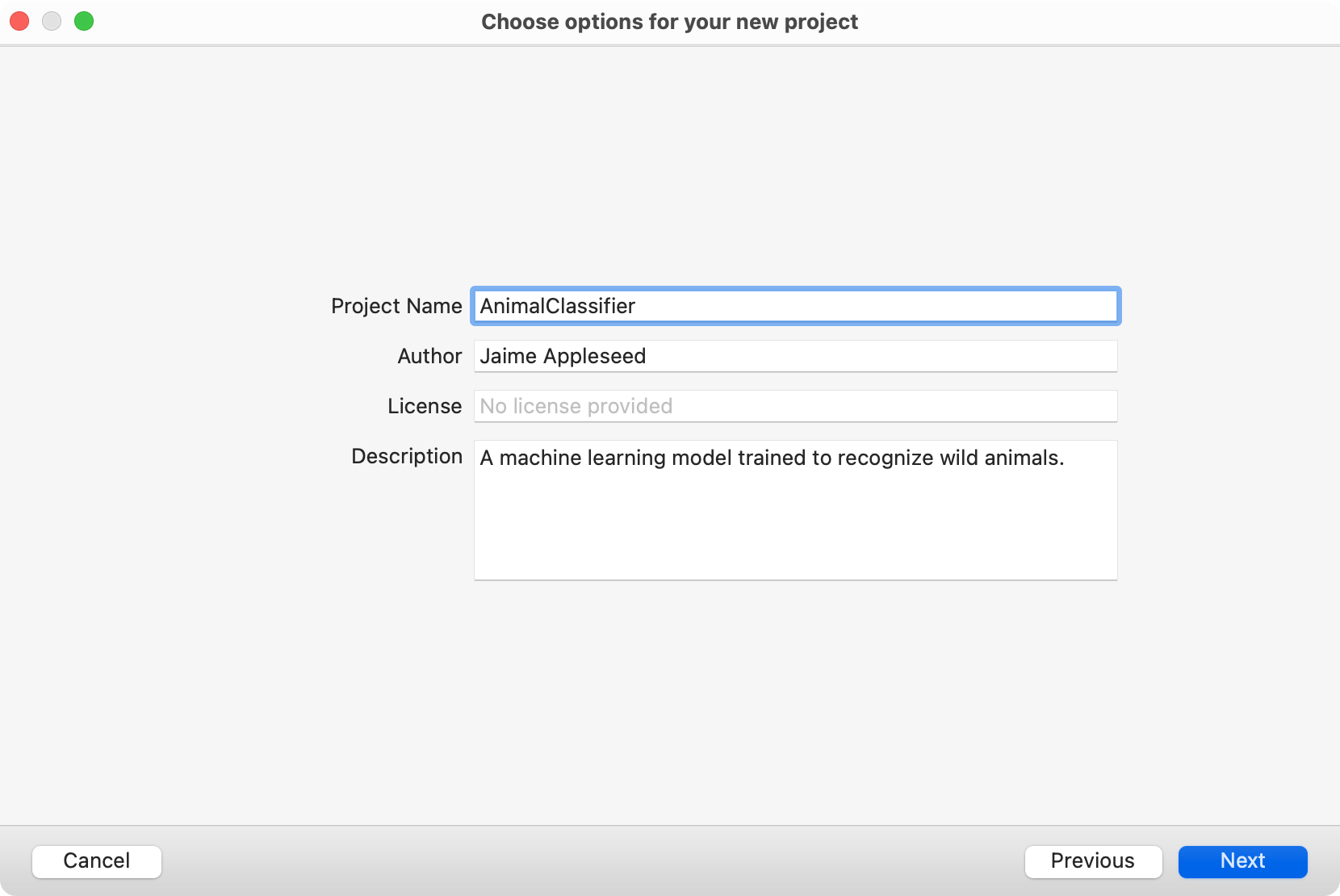
プロジェクトのデフォルト名をよりわかりやすい名前に変更します。該当する場合は、このプロジェクトに付属するモデルに関する追加情報(1人または複数の作成者や簡単な説明など)を入力します。
トレーニング用のデータセットを含むフォルダをプロジェクトウィンドウの「Training Data」にドラッグします。
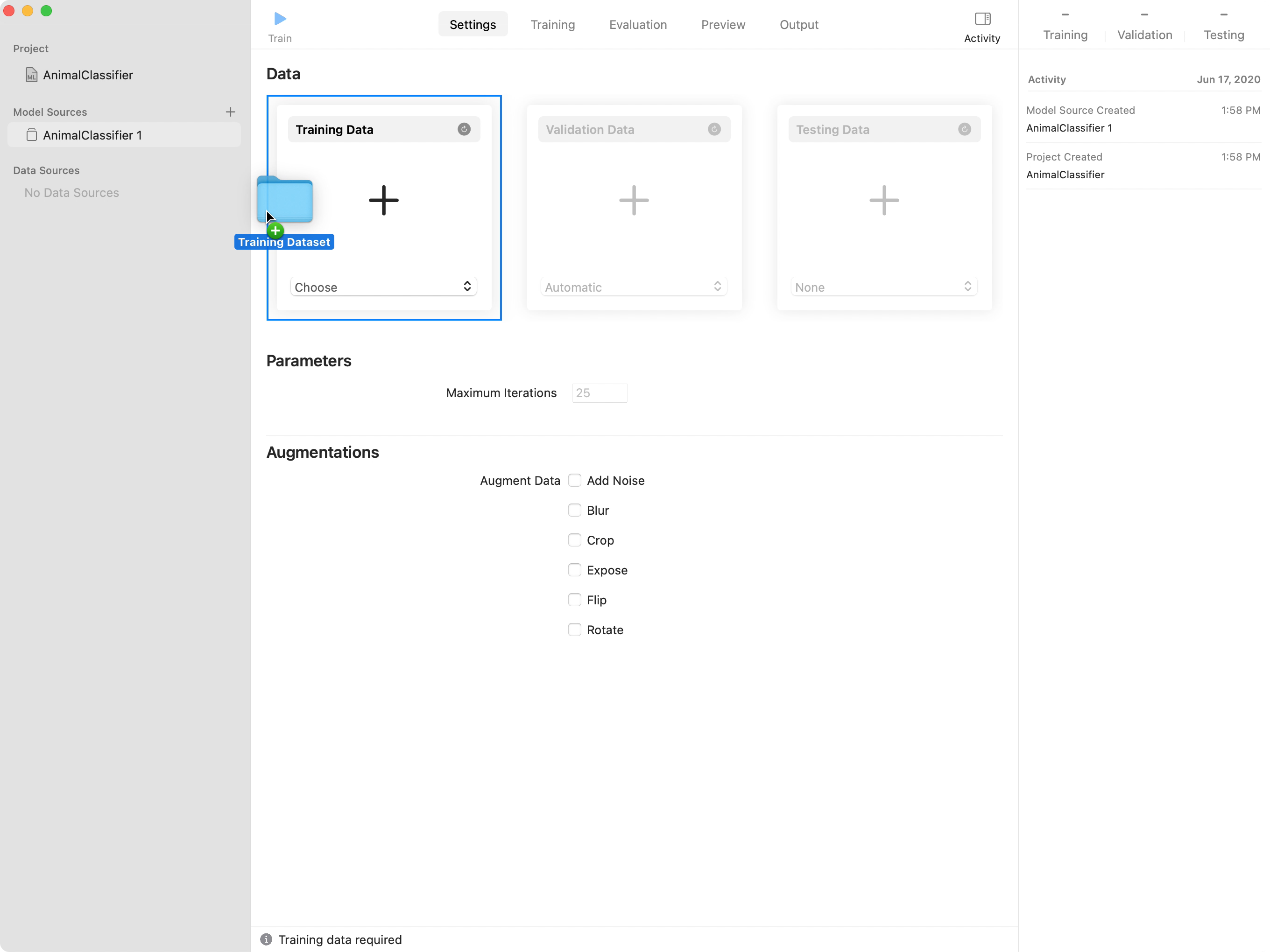
該当する場合は、テスト用のデータセットを含むフォルダをプロジェクトウィンドウの「Testing Data」にドラッグします。
トレーニングセッションで使うトレーニングイテレーションの数がわかっている場合は、「Maximum Iterations」のデフォルト値を変更します。さらに、一部または全部の画像データ拡張(水増し)をオンにすることもできます。
それぞれのデータ拡張(水増し)ではサンプル画像をコピーし、それに変換を加えるかフィルタを適用することでより多様なデータセットが生成されるため、収集するサンプルの数を増やす必要がなくなります。
「Train」ボタンをクリックして、トレーニングセッションを開始します。Create MLは、トレーニングデータセットの一部を検証データセットに即時に分離することでセッションを開始します。次に、Create MLは、エッジ、コーナー、テクスチャ、色の領域などの特徴を残りのトレーニング画像から抽出します。Create MLは画像の特徴を使って、モデルを繰り返しトレーニングし、検証データセットによってモデルの精度をチェックします。
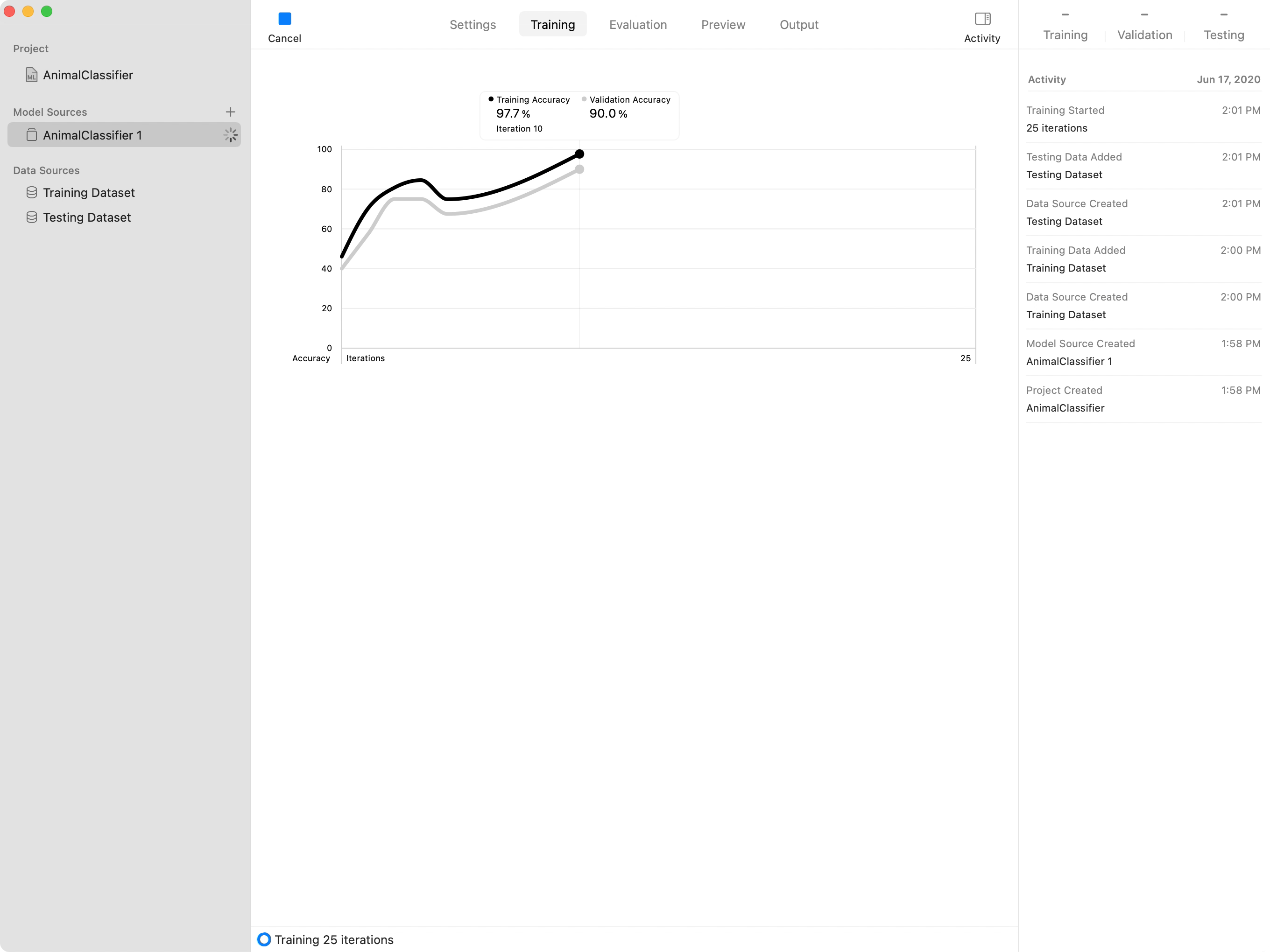
Create MLはグラフによってモデルの進行状況を示します。黒色の線とグレーの線はそれぞれ、トレーニング用のデータセットと検証用のデータセットによるモデルの精度を表しています。
Create MLは、モデルのトレーニングを終了すると、テスト用のデータセットを使ってモデルをテストします。モデルのテストが終了したら、Create MLはトレーニング、検証、テストの精度のスコアを「Evaluation」タブに表示します。通常、モデルは、トレーニングデータセットの画像から学習しているため、トレーニングデータセットに関する精度のスコアがより高く表示されます。この例では、画像分類モデルの精度が、トレーニング用の画像では100%、検証用の画像では95%、テスト用の画像では97%と正確に認識されています。
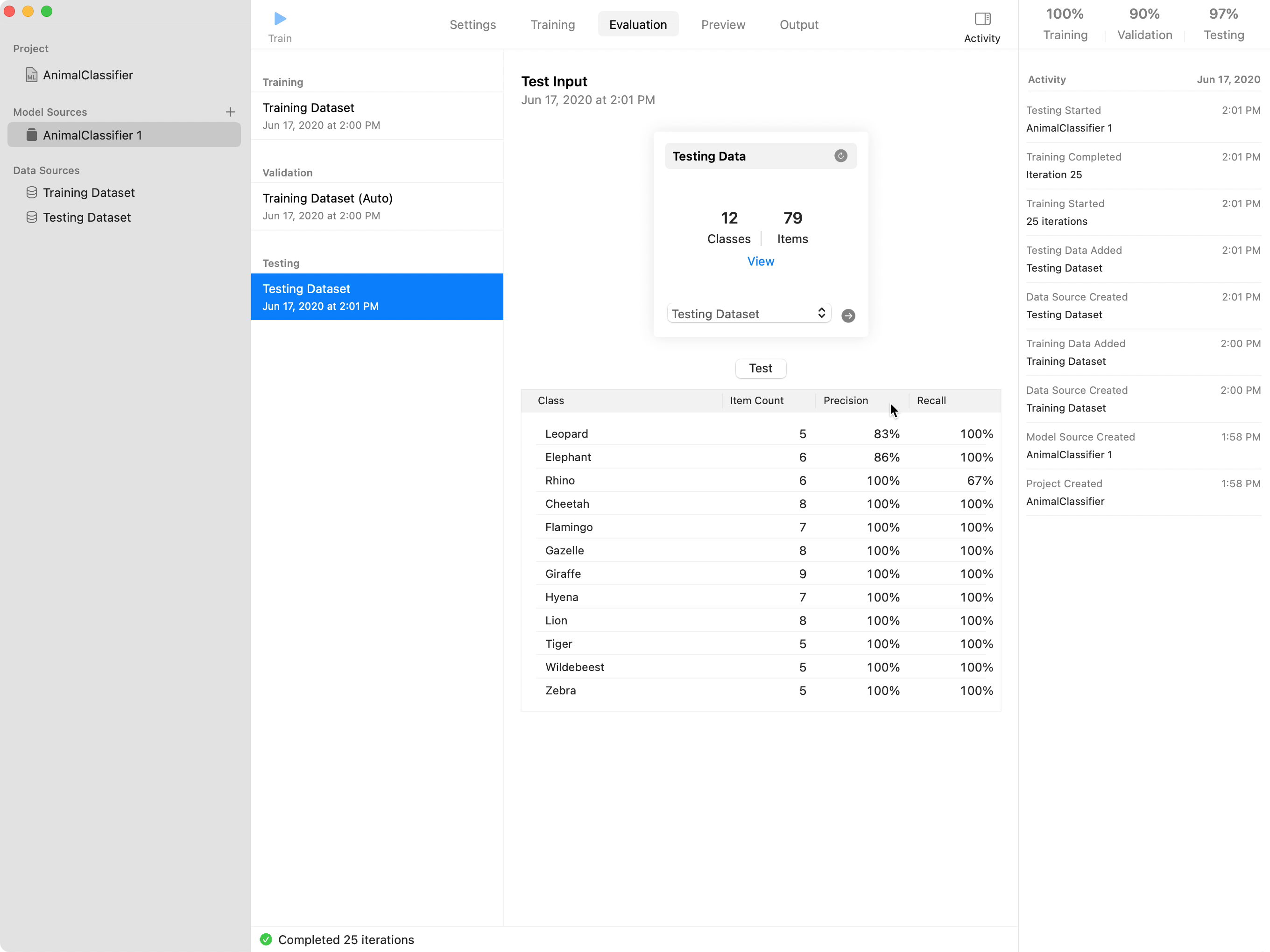
「precision」は、真陽性の数を、真陽性と偽陽性の合計値で割った数値です。「recall」は、真陽性の数を、真陽性と偽陰性の合計値で割った数値です。
評価のパフォーマンスが不十分な場合は、より多様なトレーニングデータを使って再トレーニングを行う必要があります。たとえば、画像分類器の画像データ拡張(水増し)オプションを有効にすることができます。より詳細なモデルの評価、およびモデルのパフォーマンスを高める方法については、モデルの精度の向上を参照してください。
「Preview」タブをクリックして、これまでに利用されていない画像を使ってモデルを試してみましょう。モデルの予測を確認するには、「Train」ボタンの下の列に画像ファイルをドラッグします。
モデルのパフォーマンスが十分になったら、Xcodeプロジェクトに追加できるよう、モデルをファイルシステムに(Core MLの.mlmodel形式で)保存します。「Output」タブで、次の操作を実行できます。
「Save」ボタンをクリックして、モデルをファイルシステムに保存する
「Export」ボタンをクリックして、モデルをXcodeで開く
「Share」ボタンをクリックして、メールやメッセージなどを使ってモデルを他のユーザーに送信する
ファイルを受け入れる任意の場所にモデルのアイコンをドラッグする
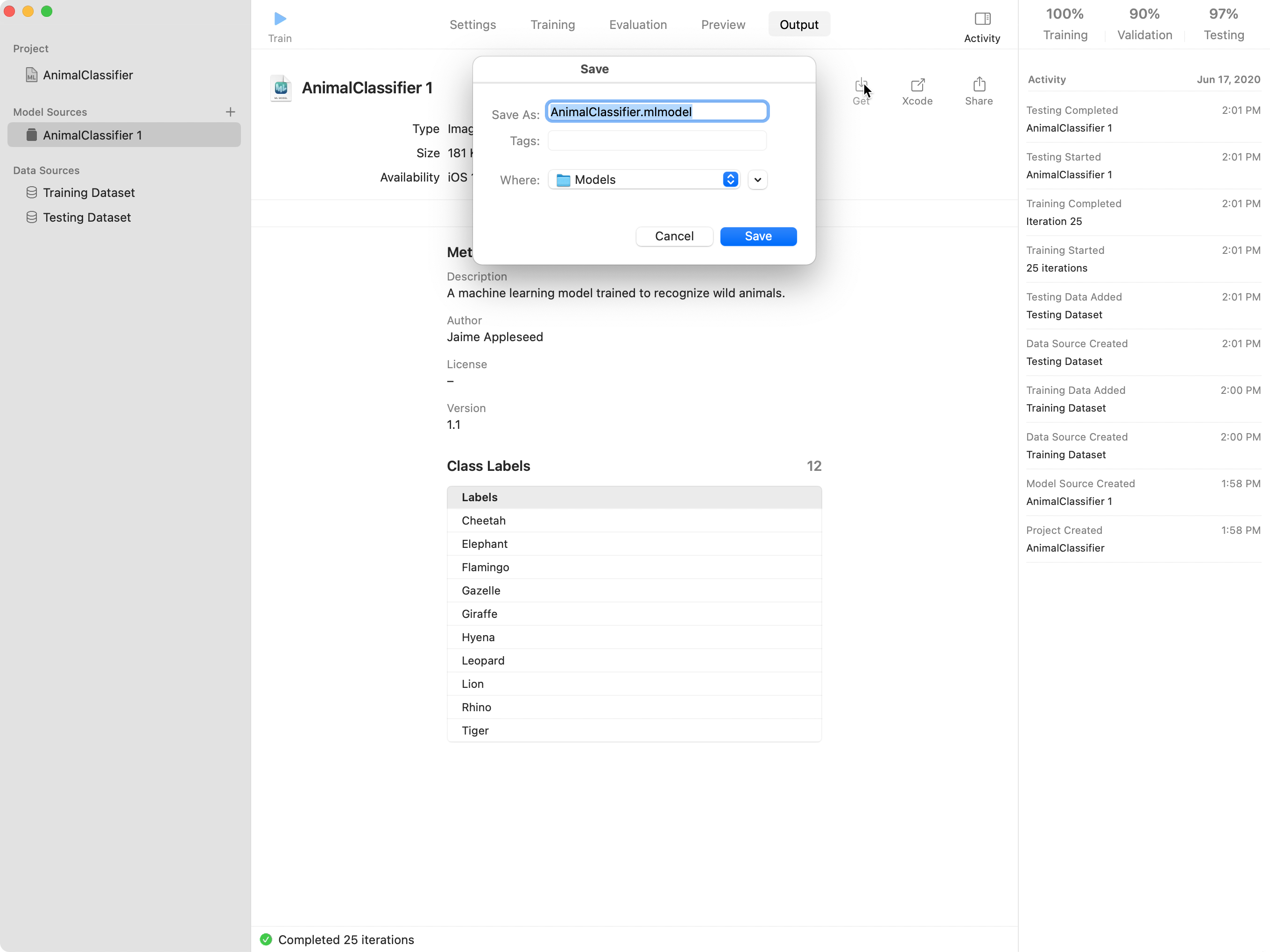
最後に、トレーニング済みのモデルをXcodeプロジェクトに追加します。たとえば、VisionとCore MLでの画像の分類(英語)のサンプルのXcodeプロジェクトに付属のモデルを、この画像分類モデルに置き換えることができます。
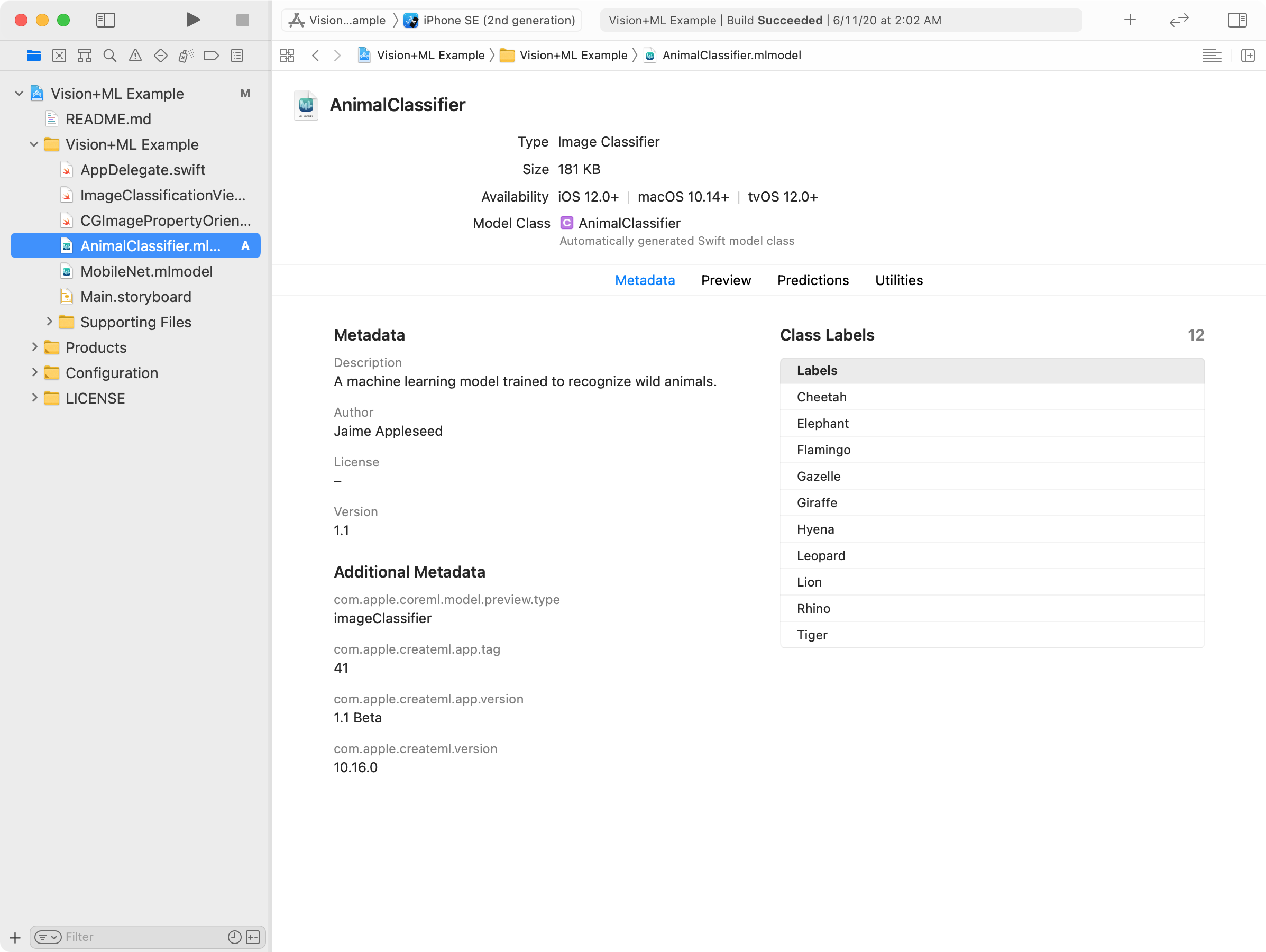
サンプルをダウンロードして、プロジェクトをXcodeで開きます。モデルファイルをナビゲーションペインにドラッグします。Xcodeで、モデルがプロジェクトに追加され、モデルのメタデータ、オペレーティングシステムの可用性、クラスラベルなどが表示されます。
作成したモデルをコードで使うには、1行を変更するだけです。プロジェクトに付属のMobileNetモデルは、Imageクラス内の一箇所のみでインスタンス化されます。
let model = try VNCoreMLModel(for: MobileNet().model)
この行を、作成したモデルのクラスに変更します。
let model = try VNCoreMLModel(for: AnimalClassifier().model)
どちらのモデルも入力に画像、出力にラベル文字列を扱うので、これらのモデルは相互に入れ替えが可能です。モデルを入れ替えると、サンプルアプリは以前と同じように画像を分類しますが、ユーザーのモデルとそれに関連付けられたラベルを使う、という点が異なります。
上記のセクションで説明したように、Create MLを使うと、わずかなコードで、機械学習の専門知識がなくても、有用な画像分類器をトレーニングすることができます。ただし、MLImage(英語)インスタンスを使って、モデルのトレーニングプロセスをスクリプト化することもできます。一般的なタスクは同じで、データを準備し、モデルをトレーニングし、パフォーマンスを評価し、Core MLモデルファイルに保存します。異なるのは、すべてをプログラムで行う、という点です。
たとえば、2つのMLImage(英語)インスタンスを初期化して、1つはトレーニング用のデータセット、もう1つはテスト用のデータセットに使うことができます。トレーニング用のデータソースを使ってinit(training(英語)で、画像分類器を初期化します。次に、テスト用のデータソースのevaluation(on:)(英語)メソッドを使って、返されるMLClassifier(英語)インスタンスの値を評価します。
struct MLImageClassifier (英語)
struct MLObjectDetector (英語)